
Top
Search
People also search for:
Stay Inspired with Instagram





Your AI model passed every test. It hit your accuracy target. You launched it. Then, three months later, it stopped working the way it did on day one. This is not a model problem. It is an MLOps problem. And it is the most common way AI investments quietly die.
Most businesses assume their AI project is done when the model launches. MLOps exists because that assumption is wrong. A model that performs well in testing will degrade in production. The data it was trained on will drift. User behavior will shift.
Edge cases, the model was never shown, will start appearing at scale. Without a structured operational practice for managing AI systems after they go live, every AI product is on a slow countdown to failure. This guide explains what MLOps actually involves, why it is the single most overlooked gap in AI software development today, and what your team needs to do differently before, during, and after launch.
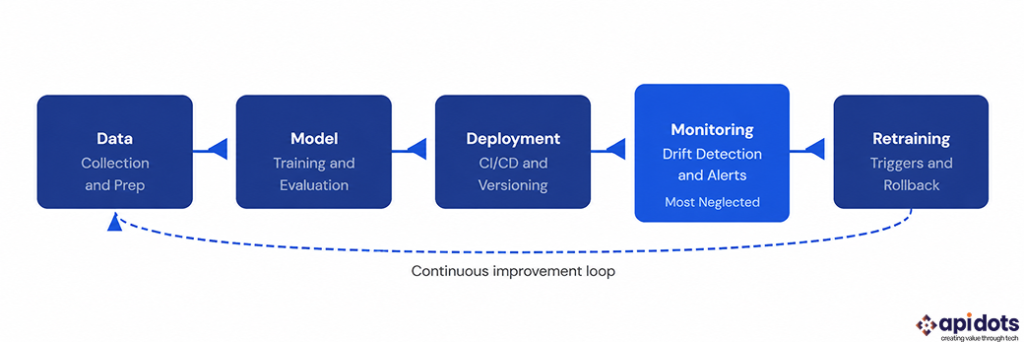
MLOps stands for Machine Learning Operations. It is the set of practices, tools, and processes that govern how AI models are deployed, monitored, maintained, and retrained in production environments. Think of it as the DevOps equivalent for AI — the discipline that bridges the gap between a model that works in a controlled environment and a model that works reliably in the real world over time.
Why is this a 2026 problem specifically? Because the AI adoption curve has now moved far enough that a large number of businesses are hitting the same wall at the same time. They built something, launched it, and are now discovering that AI in production behaves very differently from AI in development. The post on AI adoption mistakes covers the broader strategic errors businesses make, but the operational failures are the ones that are quietly costing the most money right now.
According to Gartner, 85 percent of AI projects that reach production fail to deliver their expected business value within the first year. The most consistent reason is not poor model design. It is the absence of any structured process for managing the model once it is running in the real world.

Not all AI project failures look the same. But the operational breakdowns that drive them fall into three patterns that appear repeatedly across businesses at every scale.
Model drift happens when the statistical relationship between your input data and the outputs your model was trained to predict changes over time. It does not announce itself. There is no error message. The model keeps running, keeps returning outputs, and keeps looking like it is working — while its predictions become progressively less accurate.
A fraud detection model trained on 2024 transaction patterns will start degrading as fraud tactics evolve in 2025 and 2026. A recommendation engine trained on pre-recession purchasing behaviour will produce increasingly wrong results as economic conditions shift. A customer churn model will drift as new product features change what retention actually looks like. Without drift detection built into your MLOps pipeline, none of these failures surface until a human notices that business outcomes have changed — by which point the model has been wrong for weeks or months.
Most AI development projects end at deployment. The model goes live, the development team moves on, and nobody has defined a process for retraining the model when its performance degrades. This is not a technology problem. It is a process problem, and it is one of the clearest signs that an AI development engagement did not include genuine MLOps capability.
A proper MLOps setup includes defined triggers for retraining: specific performance thresholds, data volume milestones, or time-based schedules, depending on how quickly the underlying data distribution is expected to change. Without these, the question of “when should we retrain?” gets answered with “when something visibly breaks,” which is always too late. The post on debugging AI code covers how production AI failures get diagnosed, but the smarter approach is building the monitoring that catches degradation before it becomes a crisis.
Every AI system that goes into production will eventually need a model update. The update might be a retrained version of the same model, a new architecture, or a fine-tuned variant incorporating new data. When that update degrades performance compared to the previous version, teams without a rollback process have two options: ship a hotfix under pressure or leave the degraded model running while they figure out what went wrong.
Neither is acceptable for a business-critical AI system. Model versioning and rollback capability are non-negotiable components of any MLOps setup. They are also among the most commonly absent components when businesses come to us after a failed AI launch.
The cost of ignoring MLOps is not always visible on a single invoice. It accumulates across missed predictions, degraded customer experiences, and engineering time spent firefighting problems that proper monitoring would have caught weeks earlier. Here is what the failure modes actually cost across different AI system types.
| AI System Type | Common MLOps Failure | Typical Business Impact | Time to Detection Without Monitoring |
|---|---|---|---|
| Fraud detection model | Drift as fraud patterns evolve | Rising false negatives and financial losses accumulate undetected | 45 to 90 days |
| Customer churn prediction | Feature distribution shift | Retention campaigns target the wrong customers, wasting spend | 30 to 60 days |
| Recommendation engine | Concept drift from behavioural change | Click-through and conversion rates decline | 14 to 30 days |
| Document processing AI | New document formats not present in training data | Silent extraction errors affect downstream workflows | 60 to 120 days |
| AI customer support chatbot | Intent drift as product language and customer queries evolve | Escalation rates increase and customer satisfaction declines | 21 to 45 days |
Estimated time-to-detection and business impact for common MLOps failures across AI system types. Based on Apidots production incident data and industry post-mortems, 2025 to 2026.
The pattern across every row in that table is the same: the failure is silent, the impact accumulates before anyone notices, and by the time the problem is identified, the business has already absorbed the cost. The post on AI chatbot guardrails covers one specific version of this problem in detail — how production chatbots degrade without intent detection and output monitoring built in from launch.
MLOps is not a single tool or a single team role. It is a set of practices that need to be designed into your AI software development process before the model is ever trained. Here is what the core components look like when they are implemented correctly.
| MLOps Component | What It Does | What Happens Without It |
|---|---|---|
| Data pipeline monitoring | Tracks changes in input data distribution over time | The model trains on or receives data that no longer reflects reality |
| Model performance tracking | Monitors accuracy, precision, and recall against defined thresholds | Degradation stays invisible until business outcomes change |
| Drift detection alerts | Flags when statistical properties of inputs or outputs shift | Silent failures accumulate over weeks or months |
| Model versioning and registry | Tracks every model version and its performance history | There is no rollback path when a new version performs worse |
| Automated retraining triggers | Initiates retraining when performance drops below a threshold | Manual retraining happens reactively, after damage is done |
| A/B deployment testing | Routes a subset of traffic to a new model version before full rollout | A degraded model may be fully rolled out with no safe fallback |
Core MLOps components and the production consequences of each being absent. All six are required for reliable AI system operation at any meaningful scale.
What does this look like practically for a business building AI software in 2026? It means having the MLOps conversation with your development partner before the model architecture conversation. It means budgeting for monitoring infrastructure as part of the initial build, not as a phase two addition. And it means choosing an AI development firm that can show you production monitoring dashboards from previous client systems, not just model accuracy metrics from training runs. The post on choosing an AI company covers what to ask during that evaluation.
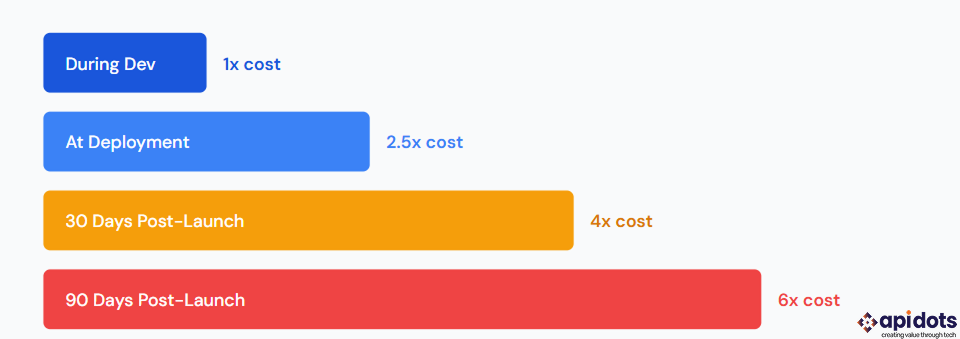
The relative cost to identify and fix an AI model failure at different stages of the development lifecycle. Catching issues during development costs a fraction of fixing them in production 90 days after launch. Source: API DOTS internal data and McKinsey AI implementation benchmarks, 2025 to 2026.
The gap exists for a straightforward reason: development firms are incentivized to ship, not to maintain. A project scoped as “build and deploy an AI model” ends at deployment. The monitoring, drift detection, and retraining infrastructure that keeps that model working belongs to a different engagement that nobody priced into the original budget.
This is not always a bad-faith decision. Many AI development teams genuinely lack MLOps expertise — they are strong at model development but weak at the operational engineering required for production reliability. According to the Stack Overflow survey, MLOps and AI infrastructure are among the most in-demand and least available skill combinations in the developer market right now. Finding teams that genuinely cover both is the harder part of the search.
When evaluating any AI software development partner, ask them to walk you through how they handled model degradation on a previous production system. Ask what their drift detection setup looked like. Ask how long it took to identify the issue and what the recovery process was. Teams with genuine MLOps experience can answer these questions in specifics. Teams without that experience will describe their testing process instead, which is not the same thing at all.
This also applies to how you approach building your own internal AI capability. The post on AI-native SaaS covers how to structure an AI product build so that operational concerns are built in from the start rather than retrofitted after launch. Retrofitting MLOps is the most expensive way to solve the problem. According to Statista, businesses that build monitoring infrastructure into their initial AI deployment spend 60 percent less on post-launch remediation than those that add it after a production failure.

We engineer and integrate custom ML software solutions end-to-end. Delivering predictive models, data insights, and measurable business results.
Get ML Development Services
Hi! I’m Aminah Rafaqat, a technical writer, content designer, and editor with an academic background in English Language and Literature. Thanks for taking a moment to get to know me. My work focuses on making complex information clear and accessible for B2B audiences. I’ve written extensively across several industries, including AI, SaaS, e-commerce, digital marketing, fintech, and health & fitness , with AI as the area I explore most deeply. With a foundation in linguistic precision and analytical reading, I bring a blend of technical understanding and strong language skills to every project. Over the years, I’ve collaborated with organizations across different regions, including teams here in the UAE, to create documentation that’s structured, accurate, and genuinely useful. I specialize in technical writing, content design, editing, and producing clear communication across digital and print platforms. At the core of my approach is a simple belief: when information is easy to understand, everything else becomes easier. Reach me at amysbrew.com