
Top
Search
People also search for:
Stay Inspired with Instagram





security controls, evaluation, and human oversight for production enterprise AI systems.
Enterprise LLM development is the work of turning a general-purpose language model into a useful, governed business system. The model is only one component. Production value comes from the surrounding architecture: approved data sources, identity and access controls, retrieval, tool integrations, evaluation, monitoring, and human oversight.
For most organizations, the central question is not whether to train a new foundation model. It is how to adapt an existing model to private information and business processes without creating a new path around security or compliance controls.
This guide explains the practical choices behind secure enterprise LLM development, including when to use RAG or fine-tuning, how permission-aware retrieval works, what to log, and where human approval should remain part of the workflow. It is based on the official AWS and Microsoft architecture documentation linked throughout.
Training a general-purpose foundation model requires exceptional compute, data engineering, evaluation, safety work, and operational expertise. That investment can make sense for a model provider or research lab. It is usually unnecessary for a company whose goal is to answer questions about internal documents, assist employees, or automate a defined workflow.
An enterprise normally creates differentiation in the system around the model. That system can connect an existing model to proprietary knowledge, enforce the organization’s permissions, call approved tools, and evaluate outputs against business requirements.
The practical decision is therefore not simply “Which model should we train?” It is “Which model and architecture meet our quality, privacy, latency, deployment, and cost requirements?” Teams should compare hosted and self-managed models using their own representative tasks rather than treating benchmark scores as a substitute for application testing.
| Approach | Best fit | Knowledge updates | Relative effort |
| Prompting and structured outputs | Clear, low-risk tasks with stable instructions | Update prompts or application logic | Lower |
| RAG | Current, private, or citable knowledge | Update the source and search index | Medium |
| Fine-tuning | Consistent behavior, terminology, classification, or style | Prepare data, retrain, and re-evaluate | Higher |
| Train from scratch | Organizations building a foundation model as a core product | Full training and serving lifecycle | Exceptional |
Relative effort depends on model choice, data quality, integrations, deployment constraints, and evaluation requirements. Fixed cost and delivery ranges are intentionally omitted because they vary substantially by use case.
Practical selection rule
Begin with the least complex approach that can pass a representative evaluation set. Add retrieval when the model needs controlled knowledge, and add fine-tuning only when measured behavior remains inconsistent after prompting, examples, and output constraints.
Retrieval-augmented generation, or RAG, combines a language model with a retrieval system. When a user asks a question, the application searches approved sources, selects relevant passages, and supplies those passages to the model as context for the answer.
RAG is useful when knowledge changes frequently, belongs in an external system of record, or needs to be cited. Microsoft describes RAG as a way to ground generative AI applications in indexed content, while its production guidance emphasizes preprocessing, retrieval quality, post-processing, and evaluation rather than treating vector search alone as a complete solution. See Azure AI Search’s RAG overview and Microsoft’s advanced RAG guidance.
A production RAG pipeline normally includes ingestion, parsing, chunking, metadata, embeddings or another retrieval representation, search and ranking, permission filtering, context assembly, generation, citation handling, and evaluation. Weakness in any one of these stages can produce a confident answer from irrelevant or incomplete evidence.
RAG and fine-tuning solve different problems. RAG changes the information available to the model at query time. Fine-tuning changes model weights so the model is more likely to perform a task in a learned way.
| Requirement | RAG | Fine-tuning |
| Frequently changing information | Strong fit | Knowledge becomes stale unless the model is updated |
| Document citations and traceability | Strong fit | Not a native knowledge-citation mechanism |
| Consistent classification, tone, or format | Can help through examples and prompts | Strong fit |
| Specialized task behavior | Provides context but does not change model weights | Strong fit |
| Fast knowledge updates | Re-index changed sources | Prepare data and run another training cycle |
Choose RAG for customer support based on current documentation, legal search across approved contracts, HR policy questions, and other tasks where evidence should come from controlled sources. Choose fine-tuning when a measured evaluation shows that the base model does not consistently follow a narrow task pattern, vocabulary, classification scheme, or response style.
Some mature systems combine the two. RAG supplies current evidence, while fine-tuning improves task behavior. Neither approach guarantees accuracy or format compliance, so production systems still need output validation and evaluation.
Important limitation
RAG can reduce unsupported answers, but it does not eliminate them. A model can misread a relevant passage, combine sources incorrectly, or answer from its prior knowledge when retrieval is weak. Evaluate retrieval relevance and answer faithfulness separately.
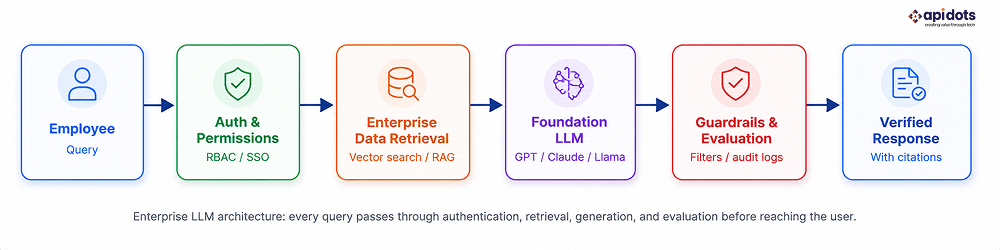
Connecting an LLM to internal data creates a new interface to company systems. Security should therefore be designed into identity, retrieval, networking, model access, tools, logging, and approval workflows from the beginning.
The governing rule is simple: a user should not receive information or perform an action through the AI system that they could not access directly. The application must enforce that rule through technical authorization, not through a prompt asking the model to behave.
AWS documentation covers complementary controls for Amazon Bedrock, including IAM permissions, KMS encryption, TLS, model invocation logging, CloudTrail events, and private connections through AWS PrivateLink. These controls are documented across multiple services and configuration guides; they are not presented by AWS as one mandatory list of exactly seven layers. See the Amazon Bedrock security documentation.
Control 1: Identity and Authorization
Authenticate every user and service. Apply least-privilege roles to data sources, model endpoints, indexes, tools, and administrative functions.
Control 2: Permission-Aware Retrieval
Filter candidate documents using the authenticated user’s permissions before any restricted passage is placed in the model context.
Control 3: Encryption and Key Management
Encrypt data at rest and in transit. Use customer-managed keys where the organization needs additional control over access, rotation, or revocation.
Control 4: Private Networking
Use private endpoints and restricted service communication where required. AWS PrivateLink can connect a VPC to Bedrock without a public internet path.
Control 5: Input, Output, and Tool Controls
Detect sensitive data, treat retrieved content as untrusted input, validate tool arguments, and restrict each tool to the minimum data and actions it needs.
Control 6: Audit and Observability
Record identity, retrieval, model, tool, and approval events according to the organization’s risk and retention requirements.
Permission filtering should occur during retrieval, not after generation. A document that the user cannot access in the source system should not be included in the prompt, citation list, cache, or response. This normally requires access-control metadata in the index and a reliable process for updating that metadata when permissions change.
Microsoft’s secure multitenant RAG guidance focuses specifically on ensuring users can access only authorized information, and Azure AI Search supports document-level access-control patterns for secure search and RAG applications. See Microsoft’s secure multitenant RAG guidance.
PII detection and input/output filtering can reduce accidental exposure, but they do not automatically prevent prompt injection. Injection defenses also require instruction separation, permission checks, tool allowlists, parameter validation, restricted credentials, output validation, and monitoring for unusual behavior.
Cloud platforms can record model invocations and API activity, but a complete audit trail often requires application-level instrumentation for user identity, retrieved passages, authorization decisions, tool calls, and approvals. AWS, for example, documents model invocation logging through CloudWatch Logs or Amazon S3 and API activity through CloudTrail.
Logs can contain prompts, responses, identifiers, or retrieved content, so they need their own access controls, redaction rules, retention periods, and incident procedures. Avoid assuming that “log everything” is automatically the safest design.
Architecture note
Microsoft’s GPT-RAG solution accelerator demonstrates an enterprise RAG pattern on Azure and includes secure deployment guidance. Treat it as a reference implementation to adapt and threat model, not as proof that every deployment is secure by default.
When an LLM can send messages, initiate payments, change permissions, update records, delete data, or interact with external systems, the workflow should classify actions by consequence, reversibility, data sensitivity, and financial impact.
A common pattern is to let the model prepare a proposed action while deterministic application logic checks permissions and risk. A human then approves high-impact actions before execution. Approval should be explicit, recorded, and tied to the exact action and parameters being authorized.
RAG addresses controlled access to knowledge, but production systems usually need several additional layers. Prompt design, structured outputs, deterministic rules, tool calling, workflow orchestration, and fine-tuning each solve a different problem.
A system prompt can define the model’s role, scope, tone, evidence requirements, refusal behavior, and output structure. Prompts should be versioned and evaluated like application code. Where downstream software depends on a schema, use structured output features and validate the result rather than relying on prose instructions alone.
Prompts are not security boundaries. An instruction such as “do not reveal confidential data” cannot replace access controls that prevent the data from reaching the model in the first place.
Tool calling lets a model request an approved function or API—for example, checking inventory, looking up an order, or preparing a report. The application, not the model, should decide which tools are available, validate every argument, enforce the caller’s permissions, and limit credentials to the narrowest possible scope.
An enterprise LLM often operates as one component in a larger workflow. It may classify a request, retrieve evidence, propose an action, route the case, and produce a draft for review. Deterministic business rules remain the better choice for fixed calculations, authorization, compliance checks, and irreversible operations.
Fine-tuning can improve performance on a narrow task when high-quality examples are available and prompt-based approaches have reached a measurable limit. It adds data preparation, privacy review, training, versioning, regression testing, and ongoing evaluation. Use it to address a demonstrated behavioral gap—not as a general-purpose place to store changing business facts.
| Technique | Primary purpose | Key control | Relative complexity |
| Prompting | Instructions, scope, tone, and reasoning context | Versioning and evaluation | Lower |
| Structured outputs | Machine-readable responses | Schema validation | Lower |
| RAG | Current, controlled knowledge | Retrieval quality and permissions | Medium |
| Tool calling | Live data and approved actions | Authorization and argument validation | Medium |
| Workflow orchestration | Multi-step business processes | State, retries, approvals, and auditability | Higher |
| Fine-tuning | Specialized task behavior | Training-data quality and regression testing | Higher |
Production quality cannot be established from a demo conversation. Teams need a representative evaluation set that reflects real users, difficult queries, permission boundaries, expected citations, failure cases, and high-risk actions.
Measure whether the retrieval system finds the right evidence before judging the final answer. Useful retrieval measures include relevance, recall, ranking quality, precision, correctness, and source freshness. Generation measures can include faithfulness to the retrieved evidence, completeness, citation accuracy, format compliance, refusal behavior, and task success.
Evaluation should include users with different roles, revoked access, malicious documents, prompt-injection attempts, malformed tool parameters, sensitive-data requests, and attempts to bypass approval. A system that answers normal questions well can still fail at authorization boundaries.
Document updates, embedding changes, index settings, prompts, model versions, and tool APIs can all alter behavior. Record these versions so a quality change can be traced to a specific configuration. Re-run regression tests before deployment and monitor production signals after release.
User feedback can reveal recurring failures, but it is incomplete and sometimes biased toward unusually good or bad experiences. Combine it with sampled reviews, automated checks, security telemetry, and task-level business outcomes.
Evaluation practice
Microsoft’s RAG evaluation guidance recommends testing the stages of the pipeline systematically rather than evaluating only the final chat response. Keep test queries, source documents, configuration, and results versioned so changes can be compared.
Platform features and preview statuses change. Verify vendor documentation and regional availability before implementation.
Primary technical references
This guide synthesizes official platform and architecture documentation and translates it into a vendor-neutral implementation framework. Claims that vary by architecture, especially project cost, delivery time, and the exact number of security controls, are not presented as universal figures.
What is enterprise LLM development?
Enterprise LLM development is the process of building a business application around a large language model. It combines the model with approved company data, access controls, retrieval systems, internal tools, evaluation, monitoring, and human oversight.
Does an enterprise need to train its own LLM?
Usually not. Most enterprises can use an existing commercial or open-weight model and customize the surrounding system. Training a foundation model from scratch is generally only practical for organizations developing the model itself as a core product or strategic capability.
When should a company use RAG instead of fine-tuning?
RAG is usually the better choice when the system needs access to current, private, or citable information. Fine-tuning is more suitable when the goal is to improve consistent behavior, terminology, classification, tone, or output formatting. Some enterprise systems use both.
Does RAG eliminate hallucinations?
No. RAG can reduce unsupported answers by grounding the model in retrieved information, but it cannot eliminate hallucinations completely. The system may still retrieve an irrelevant passage, miss important context, or misinterpret the source.
How should an enterprise secure a RAG system?
An enterprise should authenticate every user, enforce document permissions during retrieval, encrypt data, restrict network access, validate tool calls, filter sensitive information, maintain audit logs, and require human approval for high-risk actions.
What should an enterprise LLM evaluation include?
Evaluation should test retrieval relevance, answer accuracy, citation faithfulness, permission enforcement, refusal behavior, output formatting, prompt-injection resistance, tool usage, response time, cost, and overall task success.
We leverage AI, cloud, and next-gen technologies strategically.Helping businesses stay competitive in evolving markets.
Consult Technology Experts
Hi! I’m Aminah Rafaqat, a technical writer, content designer, and editor with an academic background in English Language and Literature. Thanks for taking a moment to get to know me. My work focuses on making complex information clear and accessible for B2B audiences. I’ve written extensively across several industries, including AI, SaaS, e-commerce, digital marketing, fintech, and health & fitness , with AI as the area I explore most deeply. With a foundation in linguistic precision and analytical reading, I bring a blend of technical understanding and strong language skills to every project. Over the years, I’ve collaborated with organizations across different regions, including teams here in the UAE, to create documentation that’s structured, accurate, and genuinely useful. I specialize in technical writing, content design, editing, and producing clear communication across digital and print platforms. At the core of my approach is a simple belief: when information is easy to understand, everything else becomes easier. Reach me at amysbrew.com