
Top
Search
People also search for:
Stay Inspired with Instagram





A production app already has users, permissions, data flows, uptime targets, and business rules. This guide shows how to add a useful AI capability without turning the model provider into a single point of failure or making claims your team cannot measure.
Adding generative AI to an existing application is a systems-integration project, not merely an API call. The feature must fit the product’s current authentication model, data permissions, latency budget, error handling, observability, and user expectations. A fluent model response is only one component of a dependable user experience.
The goal is therefore not “add AI everywhere.” It is to improve a valuable workflow while preserving the reliability and security of the existing application. To do that, follow the four-step process below, which is designed around that constraint.
Step 1: Audit the workflow and data
Define the user problem, baseline metric, required context, permissions, and integration surface.
Step 2: Choose the simplest viable pattern
Direct API, RAG, or model customization—based on what the feature must know and do.
Step 3: Isolate and validate the AI layer
Use a service boundary, explicit schemas, timeouts, retries, queues, and graceful fallback behavior.
Step 4: Evaluate, launch gradually, and monitor
Test representative cases, limit the initial rollout, capture feedback, and watch for regressions.
In a greenfield AI product, the team can design the data model, feedback loop, infrastructure, and user experience around model behavior. In an established product, those choices already exist, so the implementation starts with the constraints you must respect.
The AI feature must respect legacy interfaces, existing permissions, operational dependencies, and users who expect current workflows to continue working.
The most damaging retrofit mistake is to make a probabilistic external service a hard dependency of stable product behavior. Model APIs can return authentication errors, permission errors, rate-limit responses, timeouts, overload responses, or malformed outputs.
Anthropic, for example, documents distinct HTTP errors for rate limits, timeouts, server errors, and temporary overloads; official SDKs expose typed errors, allowing applications to handle them explicitly. Anthropic errors
Design rule
An AI enhancement should fail closed or fall back safely. A model outage should not prevent a user from opening a document, submitting a form, searching with the original search engine, or completing another core task that worked before the AI feature existed.
Start with a product question:
Which existing workflow has a measurable problem that a model can plausibly improve?
Good candidates usually involve repeated language work, unstructured information, classification, extraction, summarization, search, or drafting. The feature should have an observable before-and-after metric such as task completion time, escalation rate, search success, edit distance, acceptance rate, or support deflection.
Write down the user’s current task, the current result, and the cost of failure. A useful specification is narrower than “add a chatbot.” For example: “Help an authenticated account manager draft a renewal email from the customer record, while requiring the user to review and send it.” This defines the user, context, action boundary, and human approval point.
Separate information already present in the user’s request from information that must be retrieved. A summary of the text the user pasted may need no additional knowledge base. A policy assistant must retrieve current policy documents. A customer-support copilot may need account data, prior tickets, and product documentation—each with different retention and access rules.
Retrieval must preserve the application’s existing access controls. The vector store or search index is not a substitute for authorization. OWASP’s LLM verification guidance explicitly notes that RAG introduces access-control, supply-chain, and prompt-injection risks in the retrieval path.
List the internal APIs, database views, event streams, file stores, and actions the feature would use. If the model must trigger an action, the application—not the model—must validate the action, the user’s permission, and all parameters before execution. Never treat generated text or tool arguments as trusted input.
Define what “good enough” means for the workflow. OpenAI’s model-optimization guidance recommends establishing evals as a baseline, then iterating on prompts, context, and—where appropriate—fine-tuning. OpenAI model optimization
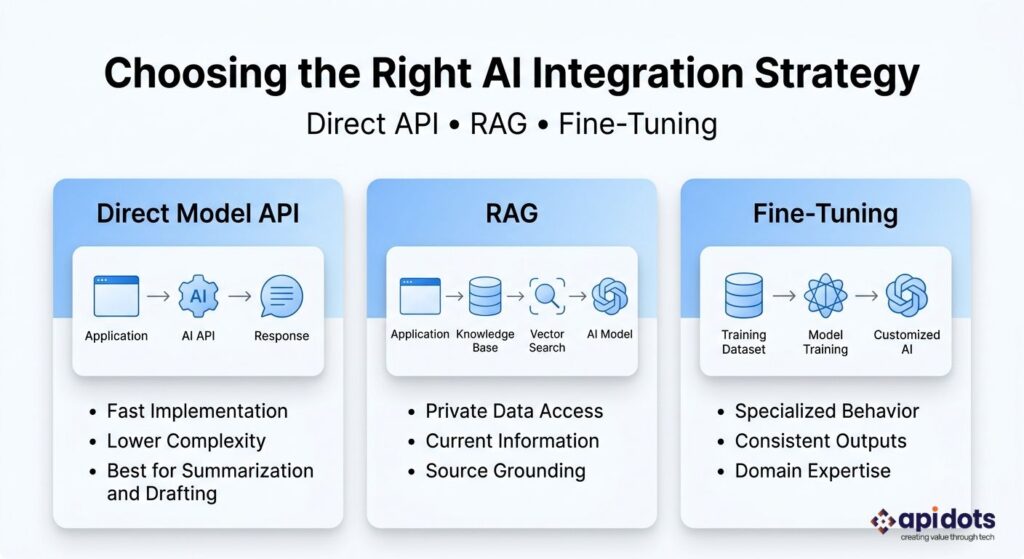
Three patterns cover most generative-AI retrofits. They are not maturity levels that every project must climb through. Choose the least complex pattern that can satisfy the measured requirement.
Image
A direct API integration sends instructions and user-provided context to a hosted model and returns text, structured data, or tool calls. It is a strong first option for bounded tasks that do not require a private knowledge base: summarizing supplied text, extracting fields, classifying a message, rewriting content, or drafting a response from context already loaded by the application.
Official SDK availability is broad but provider-specific. OpenAI currently documents official quickstarts for JavaScript/TypeScript, Python, .NET, Java, and Go. Anthropic documents general-purpose clients for Python, TypeScript, C#, Go, Java, PHP, and Ruby, with built-in streaming, retries, and error handling. OpenAI quickstart Anthropic SDKs
OpenAI integration note for 2026
OpenAI has deprecated the Assistants API and states that it will shut down on August 26, 2026. The official migration guide directs integrations toward the Responses API and Conversations architecture. Existing Assistants-based implementations should have a migration plan rather than treating the old interface as a long-term dependency. Migration guide
RAG combines retrieval with generation, so the model receives relevant content from an external knowledge source before composing an answer. It is appropriate when the response must be grounded in proprietary, domain-specific, or frequently changing data. OpenAI’s file-search documentation describes semantic and keyword retrieval from vector stores, while Microsoft describes RAG as the process of grounding model responses in proprietary content.
A production RAG pipeline is more than chunking and embeddings. It needs ingestion, document freshness, metadata, permission filtering, retrieval-quality evaluation, source handling, and defenses against malicious instructions embedded in retrieved content. A coherent answer is not evidence that the right document was retrieved.
Customization can help when a measured, task-specific behavior remains inconsistent despite strong prompting, examples, structured output, tools, and retrieval attempts. Typical goals include consistent style, classification behavior, domain-specific task performance, or predictable output structure, not keeping factual knowledge current.
Do not assume a provider’s fine-tuning product is permanently available. OpenAI’s official fine-tuning best-practices page says its fine-tuning platform is being wound down and is no longer accessible to new users. Provider support, eligible models, and migration paths must be verified before architecture or procurement decisions are made.
Relative guidance, not a universal delivery estimate
| Pattern | Best Fit | Required Data | Relative Effort | Main Watch-outs |
| Direct Model API | Summarization, extraction, drafting, classification, and content transformation | Current request and application-supplied context | Lowest | Prompt injection, output validation, latency, cost, rate limits, and provider dependence |
| RAG | Private, proprietary, domain-specific, or frequently changing knowledge | Documents or records that can be indexed with appropriate metadata and permissions | Medium | Retrieval quality, stale content, permission leakage, poisoned documents, and citation quality |
| Customization / Fine-tuning | Persistent, measured gaps in model behavior, accuracy, style, or consistency | High-quality task examples and a separate evaluation dataset | Highest | Provider availability, training-data quality, regression risk, ongoing maintenance, and privacy |
Exact delivery time cannot be authenticated as a general benchmark; estimate after the data, integration, security, and evaluation audit.
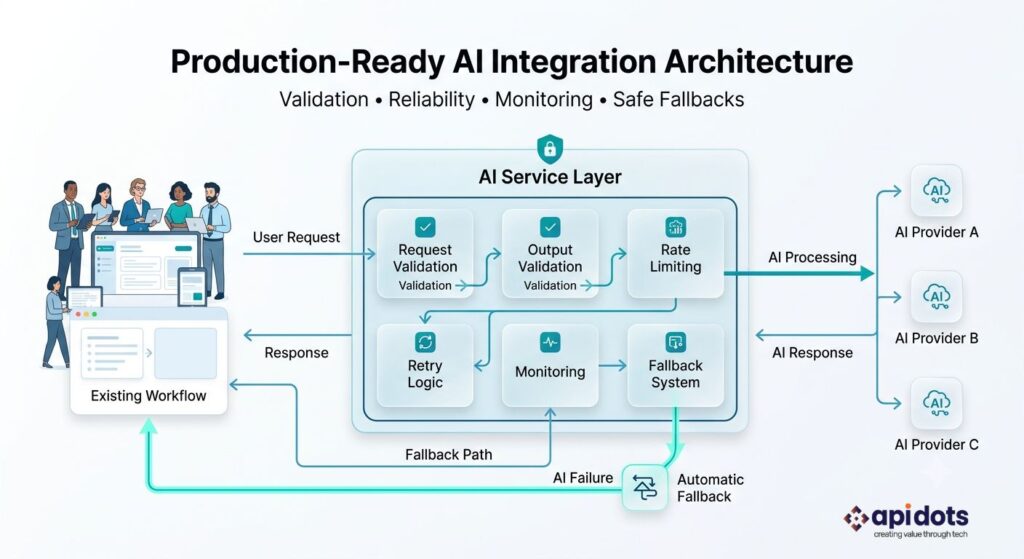
Model calls should sit behind an application-owned adapter or service. The rest of the product should depend on a stable internal contract—not on a provider-specific response object. This makes it possible to change models, add caching, apply validation, route traffic, or disable the feature without rewriting core workflows.
Handle authentication failures, permission failures, rate limits, provider errors, timeouts, overload responses, content-policy refusals, and schema-validation failures separately. Retries should be limited, use backoff and jitter, and only be applied to failures that are safe to retry. Long-running operations should use streaming, asynchronous jobs, or queues instead of holding a synchronous request open indefinitely.
When the feature needs structured data, it requires a schema and validates it on the server side. When the model proposes a tool call or action, authorize and validate it exactly as you would any untrusted external request. The application remains responsible for business rules, permissions, and side effects.
Define a non-AI fallback for every user-facing path. A model outage should not block core tasks; it should route users to the existing workflow or a safe fallback.
Never embed provider keys in browser or mobile application code. OpenAI’s production guidance recommends keeping keys out of source code and public repositories, using environment variables or a secret-management service, separating staging and production projects, and planning for rate limits. OpenAI production guidance
Recommended internal contract
Return a stable object such as {status, result, confidenceSignal, citations, fallbackUsed, and requestId}. Do not leak provider-specific response shapes throughout the application. Keep prompts, models, schemas, and safety settings versioned so a rollout can be compared or rolled back.
Generative systems are variable: the same input can produce different outputs. OpenAI’s evaluation guidance therefore recommends structured evals rather than relying only on traditional deterministic tests. OpenAI evaluation guidance
Use real or realistic examples from the target workflow, including normal cases, edge cases, ambiguous inputs, unsafe requests, missing context, long inputs, multilingual inputs where relevant, and cases that should trigger a fallback or human review. Keep an untouched holdout set for regression testing.
For RAG, measure retrieval relevance and permission correctness separately from answer quality. For tool-using systems, evaluate whether the correct tool was selected, whether arguments were valid, and whether the application correctly accepted or rejected the proposed action. For drafting features, track how often users accept, edit, or discard the output.
Start with internal users, then a small opt-in cohort, then a controlled percentage rollout. Compare the AI-assisted workflow with the current baseline. Maintain a kill switch and preserve the non-AI path until the feature meets its quality, safety, latency, and cost thresholds.
Observability is necessary, but “log everything” is not a safe default. Record the minimum information needed to diagnose performance, redact or tokenize sensitive fields, restrict access, define retention periods, and separate product analytics from security audit data. NIST’s Generative AI Profile identifies privacy, information integrity, information security, and human-AI configuration as material risk areas to manage across the lifecycle. NIST AI 600-1 overview
| Failure Mode | Why It Happens | Recommended Control |
| A provider incident breaks a core workflow | The model call is tightly coupled to existing business logic. | Use a service boundary, timeouts, circuit breakers, and a non-AI fallback. |
| Private content leaks through retrieval | The index does not enforce tenant, role, or document-level permissions. | Use permission-aware retrieval, metadata filters, and authorization testing. |
| A fluent but incorrect answer is accepted | Coherence and confidence are mistaken for factual accuracy. | Apply grounding, display sources, run task-specific evaluations, and require human review for high-impact decisions. |
| Generated action causes damage | Tool arguments or model-generated instructions are trusted without validation. | Use schema validation, least-privilege access, explicit authorization, and confirmation for consequential actions. |
| Quality regresses silently | There is no fixed evaluation set or comparison between releases. | Use versioned prompts and models, regression evaluations, staged rollouts, and rollback procedures. |
| Sensitive prompts are retained unnecessarily | Observability and logging were designed without data-minimization controls. | Apply redaction, access controls, retention limits, and regular reviews of provider data policies. |
What does it mean to integrate generative AI into an existing app?
It means adding a model-powered capability such as summarization, drafting, extraction, search, classification, or question answering to software that is already in production. The AI layer should operate through a defined service boundary and should not replace stable core functionality unless that replacement has been deliberately tested and approved.
Do I need to rebuild my app to add generative AI?
Usually, no. Most existing applications can add generative AI through an API or a separate AI service connected to the current backend. The integration should be introduced gradually so the existing business logic, permissions, databases, and user experience continue to work reliably.
What is a sensible first AI feature?
A good first feature is narrow, useful, measurable, and easy to reverse if it does not perform as expected. Common starting points include summarizing documents, drafting responses, extracting structured information, classifying requests, or helping users search approved content. Avoid beginning with fully autonomous actions or high-impact decisions.
When should an app use RAG?
An app should use retrieval-augmented generation, or RAG, when the model needs access to private, proprietary, domain-specific, or frequently changing information. RAG retrieves relevant content at query time and supplies it to the model, helping the response stay grounded in approved sources. It is especially useful when answers need citations or permission-aware access to internal documents.
Should fine-tuning be the first integration step?
Usually not. Prompt design, structured outputs, retrieval, workflow controls, and evaluation should normally be tested first. Fine-tuning becomes more appropriate when there is a persistent and measurable gap in behavior, formatting, tone, or task consistency that cannot be solved reliably through simpler integration methods.
How do I stop an AI integration from breaking the existing product?
Keep the AI capability behind a clear service boundary and add timeouts, retries, circuit breakers, monitoring, and non-AI fallbacks. Validate model outputs before they affect application data or trigger actions. High-impact actions should require explicit authorization or human confirmation, and new versions should be released gradually with rollback options.
How long does AI integration take?
The timeline depends on the feature, data readiness, security requirements, existing architecture, and level of evaluation required. A narrow API-based feature may be delivered relatively quickly, while a permission-aware RAG system or customized model workflow may require substantially more design, testing, and operational work. Any estimate should be based on the specific application rather than a universal timeline.
How should sensitive data be handled?
Sensitive data should be minimized, encrypted, access-controlled, and shared with the model only when necessary. Teams should review provider data retention and training policies, redact unnecessary personal or confidential information, restrict access to logs, enforce tenant and document permissions, and establish clear rules for retention and deletion. Regulated or high-risk use cases may also require legal, security, and compliance review.
Start with a workflow and architecture audit, establish a measurable baseline, and prove one bounded feature behind a safe service boundary before expanding the scope. Discuss an AI integration audit.
We leverage AI, cloud, and next-gen technologies strategically.Helping businesses stay competitive in evolving markets.
Consult Technology Experts
Hi! I’m Aminah Rafaqat, a technical writer, content designer, and editor with an academic background in English Language and Literature. Thanks for taking a moment to get to know me. My work focuses on making complex information clear and accessible for B2B audiences. I’ve written extensively across several industries, including AI, SaaS, e-commerce, digital marketing, fintech, and health & fitness , with AI as the area I explore most deeply. With a foundation in linguistic precision and analytical reading, I bring a blend of technical understanding and strong language skills to every project. Over the years, I’ve collaborated with organizations across different regions, including teams here in the UAE, to create documentation that’s structured, accurate, and genuinely useful. I specialize in technical writing, content design, editing, and producing clear communication across digital and print platforms. At the core of my approach is a simple belief: when information is easy to understand, everything else becomes easier. Reach me at amysbrew.com